随着企业数据量的爆炸式增长与数据处理需求的日益复杂,构建一个统一、高效、可扩展的数据湖已成为现代数据架构的核心。在云原生时代,阿里云推出的JindoFS应运而生,它不仅仅是一个分布式文件系统,更是连接大数据计算引擎与多样化云存储的高性能数据湖存储加速方案,为云上大数据处理提供了全新的数据处理与存储服务范式。
一、JindoFS的核心定位与架构
JindoFS的设计初衷是为了解决传统大数据架构在云上面临的挑战,如存储与计算分离带来的数据访问延迟、跨云存储互通性差以及成本控制等问题。其核心架构分为两个关键部分:
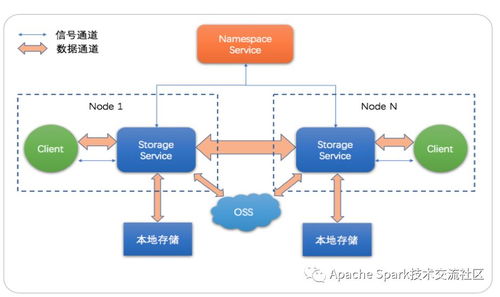
- 存储服务层:JindoFS本身并不直接持久化存储原始数据,而是作为一个智能的“缓存与加速层”,后端可以无缝对接阿里云对象存储OSS、分布式文件存储NAS以及HDFS等多种存储系统。它将热数据缓存在本地或高速云盘(如ESSD)上,形成一层高性能缓存,从而显著提升数据访问速度。
- 数据访问层:它实现了与HDFS高度兼容的接口,这意味着像Spark、Flink、Hive、Presto等主流大数据计算引擎无需任何修改或仅需极简配置,即可像访问原生HDFS一样访问JindoFS,实现了计算与存储的真正解耦与弹性伸缩。
二、作为高性能数据湖存储方案的关键特性
JindoFS通过一系列创新设计,确保了其在云上数据湖场景中的高性能表现:
- 智能缓存与分级存储:系统能自动识别热点数据,并将其缓存在低延迟的本地存储或ESSD上。冷数据则沉降到成本更低的对象存储OSS中。这种智能分层策略在保证热数据访问性能的最大化降低了总体存储成本。
- 极致的数据访问性能:通过内存级缓存、SSD加速、高效的元数据管理以及优化的数据读写路径,JindoFS能为大数据作业提供近乎本地HDFS的I/O性能,尤其适用于交互式查询、机器学习训练等对延迟敏感的场景。
- 计算存储分离与弹性:得益于与云存储的深度集成,计算资源(如E-MapReduce集群)可以根据任务需求独立、弹性地扩缩容,而数据持久化在云端对象存储中,无需随计算资源迁移,极大地提升了资源利用率和运维灵活性。
- 统一命名空间与数据一致性:JindoFS提供了统一的文件系统视图,无论数据实际存储在OSS还是其他后端,对上层应用透明。它保证了强一致性的数据语义,确保数据处理结果的准确性。
三、提供的数据处理与存储服务价值
在实际应用中,JindoFS为企业的数据平台提供了全方位的服务价值:
- 加速大数据计算与分析:直接替换传统HDFS,为Spark SQL、Hive等批处理作业以及Flink流处理作业提供高速数据读写能力,缩短作业运行时间,提升数据分析效率。
- 支撑AI/ML与交互式查询:为TensorFlow、PyTorch等AI框架提供高性能的数据加载服务,加速模型训练迭代。满足Presto、Impala等交互式查询引擎对低延迟数据扫描的苛刻要求。
- 简化数据湖管理与运维:用户无需再维护庞大的、与计算绑定的HDFS集群。数据统一存储在持久、高可用的对象存储中,由JindoFS统一管理缓存、元数据和访问加速,运维复杂度大幅降低。
- 优化总体拥有成本(TCO):利用对象存储近乎无限的扩展性和按量付费的模式,结合智能缓存减少不必要的冗余数据副本和高速存储用量,实现了性能与成本的最佳平衡。
- 增强数据流动性:作为连接器,JindoFS便于数据在云上不同存储服务(如OSS、数据库、数据仓库)之间高效流动,助力构建统一的企业级数据湖仓一体化架构。
###
JindoFS是云原生大数据演进过程中的一个重要技术创新。它巧妙地弥合了弹性、经济的云存储与高性能、兼容性强的数据访问需求之间的鸿沟。通过将“缓存加速”与“存储服务”深度融合,JindoFS不仅提供了一套高性能的数据湖存储方案,更重塑了云上数据处理的服务模式,让企业能够更专注于从数据中挖掘价值,而非纠结于底层基础设施的复杂性与性能瓶颈。对于正在或计划将大数据平台迁移上云,并追求极致性能与成本效率的企业而言,JindoFS无疑是一个极具吸引力的战略选择。