在当今数据驱动的时代,构建一个高效、可靠且可扩展的数据仓库是企业实现数据价值转化的关键基石。数据仓库架构不仅定义了数据从源头到最终分析的流动路径,还决定了系统的性能、成本与易用性。本文将系统性地阐述数据仓库的核心架构概念,并重点聚焦于数据处理与存储服务这两大关键领域,介绍主流的工具选型及其应用场景。
一、数据仓库核心架构概念
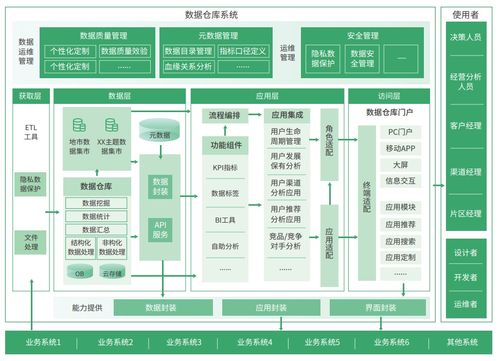
数据仓库架构通常遵循分层设计思想,旨在将复杂的ETL(提取、转换、加载)流程、数据存储与数据应用解耦。经典的分层模型包括:
- 数据源层:原始数据的来源,包括业务数据库、日志文件、API接口、物联网设备等。
- 数据集成/处理层:负责数据的抽取、清洗、转换、集成和加载,是数据质量与一致性的保障。
- 数据存储层:存储经过处理后的结构化数据,是数据仓库的核心,为上层应用提供统一的、历史的、主题导向的数据视图。通常包含ODS(操作数据存储)、数据仓库主题域、数据集市等。
- 数据服务/应用层:面向最终用户,提供数据分析、报表、即席查询、数据挖掘等能力,工具包括BI平台、数据科学工作台等。
现代数据仓库架构正从传统的单体式、批处理导向,向云原生、流批一体、湖仓一体的方向演进,强调弹性、实时性与低成本。
二、三大类组件工具选型聚焦:数据处理与存储服务
围绕数据处理与存储这两个紧密相连的核心环节,工具选型可归纳为以下三大类:
第一类:批处理与ETL/ELT工具
此类工具专注于大规模数据的周期性处理任务,是构建数据仓库的传统主力。
- 传统ETL工具:如 Informatica PowerCenter, IBM DataStage, Talend。它们提供图形化开发界面,功能强大,但通常部署在本地,扩展性和成本较高。
- 开源批处理框架:以 Apache Spark 为代表。凭借其内存计算和丰富的API(Scala, Python, SQL),Spark在性能和处理复杂逻辑方面优势明显,是构建现代数据流水线的主流选择。搭配 Apache Airflow 或 Dagster 等调度工具,可以构建健壮的批处理工作流。
- 云原生全托管服务:各大云厂商提供的无服务器ETL服务,如 AWS Glue, Azure Data Factory, Google Cloud Dataflow。它们免运维、按需付费,与云存储和云数据仓库无缝集成,极大地降低了运维复杂度。
选型考量:数据处理逻辑复杂度、团队技能栈(偏好编码还是图形化)、对实时性的要求、与现有云生态的集成度以及总体拥有成本(TOC)。
第二类:实时/流处理工具
为满足实时分析、监控和即时决策的需求,流处理组件不可或缺。
- 流处理框架:Apache Flink 因其高吞吐、低延迟、精确一次(exactly-once)语义和强大的状态管理,已成为流处理领域的事实标准。Apache Spark Streaming(微批处理模型)和 Apache Kafka Streams(轻量级库)也是常见选择。
- 流式ETL与消息队列:Apache Kafka 不仅是高性能的消息队列,其 Kafka Connect 组件可用于构建流式数据管道,ksqlDB 支持对流数据执行SQL查询。Apache Pulsar 是另一个云原生友好的消息流平台。
- 云托管服务:如 Amazon Kinesis Data Streams/Analytics, Google Cloud Dataflow(支持流处理),Azure Stream Analytics。它们提供了开箱即用的流数据处理能力。
选型考量:延迟要求(亚秒级、秒级、分钟级)、数据吞吐量、事件时间处理与乱序容忍能力、与上下游系统的集成。
第三类:数据存储与计算引擎(核心存储服务)
这是数据仓库的“大脑”与“仓库”,负责海量数据的存储和高效查询。
- 云数据仓库:代表是 Snowflake, Amazon Redshift, Google BigQuery, Azure Synapse Analytics。它们采用存储与计算分离的架构,弹性伸缩,按需付费,并内置了强大的MPP(大规模并行处理)SQL查询引擎,是当前企业上云的首选。
- 大数据SQL查询引擎(湖仓一体):如 Presto/Trino, Apache Hive, Dremio。它们可以对存储在数据湖(如AWS S3, Azure Data Lake Storage, HDFS)上的原始或半结构化数据直接进行高速SQL查询,推动了湖仓一体架构的普及。
- 开源MPP数据库:如 Greenplum, ClickHouse。Greenplum基于PostgreSQL,适合复杂的分析负载;ClickHouse则以极致的单表查询速度著称,适用于实时日志分析等场景。
选型考量:数据规模与增长预期、查询模式(复杂分析 vs. 点查询)、并发用户数、对半结构化/非结构化数据的支持、成本模型(存储与计算分离 vs. 一体)、是否需要与现有Hadoop生态兼容。
三、与趋势
数据处理与存储服务的选型并非孤立进行,而需置于整体架构中通盘考虑。当前趋势显示:
- 云原生与全托管服务成为主流,降低运维负担。
- 流批一体架构兴起,如Flink和Spark Structured Streaming,使用同一套API处理有界和无界数据。
- 湖仓一体打破数据湖与数据仓库的壁垒,通过Presto、Spark或Delta Lake、Iceberg、Hudi等表格格式,在低成本存储上实现数据仓库的性能与管理能力。
企业在选型时,应结合自身的数据规模、业务场景(实时还是离线为主)、技术团队能力及预算,选择最适配的技术组合。一个典型的现代架构可能是:使用Kafka/Flink处理实时流,使用Spark/Airflow处理批量数据,最终将处理好的数据存储于Snowflake/BigQuery或S3+Trino的湖仓一体平台上,供BI工具和数据分析师使用。通过合理的架构设计与工具选型,企业能够构建出敏捷、高效且面向未来的数据基石。